


![[下载/搬运/纪录片/熟肉]Homotherapy(以爱之名:同志矫正治疗)[1080P][已完结][内嵌][2.73G][2019]](https://yuri.website/wp-content/uploads/thumb/2022/02/fill_w372_h231_g0_mark_p2632286342.webp)


![[下载/搬运/文学研究/汉译][桑梓蘭] The Emerging Lesbian: Female Same-Sex Desire in Modern China(浮現中的女同性戀——現代中國的女同性愛欲) [王晴鋒译] [臺大出版中心][已完结][2014]](https://yuri.website/wp-content/uploads/thumb/2022/01/fill_w372_h231_g0_mark_1939a99778c51976e_1_post.webp)





![[安利/音声/熟肉]ユビノタクト TS百合系列 资源汇总/剧情时间线整理2.0](https://yuri.website/wp-content/uploads/thumb/2024/08/fill_w372_h231_g0_mark_24783d664e02bd3ad_1_post.webp)
![[安利/游戏] 百合文字冒险《岩倉アリア》 [2024]](https://yuri.website/wp-content/uploads/thumb/2024/06/fill_w372_h231_g0_mark_9731e61511876800_1_post.webp)
![[安利/安价/熟肉]组曲&哈士奇考古笔记[未完结][2008]](https://yuri.website/wp-content/uploads/thumb/2024/03/fill_w372_h231_g0_mark_455d38d4bfa7166_1_post.webp)
![[在线/原创/小说]三无娘[堇色年华][中篇]](https://yuri.website/wp-content/uploads/thumb/2022/01/fill_w372_h231_g0_mark_1405e3bee5d1661_1_post.webp)
![[在线/同人/绘画]砂糖x盐[MaidCode幺零二三][happy sugar life同人]](https://yuri.website/wp-content/uploads/thumb/2024/10/fill_w372_h231_g0_mark_453aa0770dc6cd30_1_post.webp)
![[在线/同人/绘画]糖盐[MaidCode幺零二三][happy sugar life同人]](https://yuri.website/wp-content/uploads/thumb/2024/09/fill_w372_h231_g0_mark_453676fd5369926e_1_post.webp)
![[在线/同人/绘画]砂糖x盐[MaidCode幺零二三][happy sugar life同人]](https://yuri.website/wp-content/uploads/thumb/2024/08/fill_w372_h231_g0_mark_4534c6c64be55e37_1_post.webp)
![[在线/同人/绘画] 仙宫13 [MaidCode1023][一周一次买下同班同学的那些事同人]](https://yuri.website/wp-content/uploads/thumb/2024/05/fill_w372_h231_g0_mark_45391535d266c8c2_1_post.webp)
![[在线/首发/漫画/熟肉][深海 紺]恋より青く(比恋爱更青涩)[提灯喵汉化组][コミックオギャー!!][连载至18话][2022]](https://yuri.website/wp-content/uploads/thumb/2022/09/fill_w372_h231_g0_mark_01-7.webp)
![[在线/首发/漫画/熟肉][玉崎たま]無力聖女と無能王女~魔力ゼロで召喚された聖女の異世界救国記~(无用圣女与无能王女~被召唤至异世界的零魔力圣女救国纪)[提灯喵汉化组][コミック百合姫][连载中][更新至第6话][2024]](https://yuri.website/wp-content/uploads/thumb/2024/05/fill_w372_h231_g0_mark_72.webp)
![[在线/首发/漫画/熟肉][ひあるろん&達磨]小春と湊(小春和凑)[提灯喵汉化组][コミック百合姫][连载至21][2022]](https://yuri.website/wp-content/uploads/thumb/2022/11/fill_w372_h231_g0_mark_468.webp)
![[在线/首发/漫画/熟肉][森]姉になりたい義姉VS百合になりたい義妹(绝对想当姐姐的义姐VS绝对想搞百合的义妹)[提灯喵汉化组][マグシブ][连载至50话][2022]](https://yuri.website/wp-content/uploads/thumb/2024/10/fill_w372_h231_g0_mark_13-49.webp)
![[在线/翻译/首发/小说/熟肉][原作:動画投稿少女 作者:日日綴郎]【发布者自译】【真夜中パンち】深夜重拳[2024] 完结(不知道还会不会出)](https://yuri.website/wp-content/uploads/thumb/2024/08/fill_w372_h231_g0_mark_QQ截图20240815103846.webp)
![[在线/首发/小说/熟肉]ALTDEUS: Beyond Chronos Decoding the Erudite(阿尔特斯:超越时空 解读朱莉)[个人翻译][短篇小说][已完结][2021]](https://yuri.website/wp-content/uploads/thumb/2024/08/fill_w372_h231_g0_mark_973161b1b510a60c_1_post.webp)
![[在线/首发/小说/熟肉]まな板のうえの恋(砧板上的爱/Love upon the Chopping Board)[发布者自译][6/15][1993]](https://yuri.website/wp-content/uploads/thumb/2024/02/fill_w372_h231_g0_mark_13537ac46652cba3ed_1_post.webp)
![[在线+下载/搬运/动画/生肉+熟肉]海のまにまに(任由海波荡漾)[Aki惊蛰][4K][1080P][已完结][YouTube][Bilibili][MV][YOASOBI][2023]](https://yuri.website/wp-content/uploads/2023/03/999.webp)
![[在线/转载/纸动画][推特]爱的日子[21MB][2022]](https://yuri.website/wp-content/uploads/thumb/2022/05/fill_w372_h231_g0_mark_MGT@0U4YYIRU6TA@QSN.webp)
![[在线+下载/首发/音声/熟肉]【魔法少女にあこがれて】【ASMR】マジアベーゼにいたずらされて【耳ふー・咀嚼音・耳かき】(【憧憬成为魔法少女】【ASMR】魔法枫糖的恶作剧时间【吹耳 · 咀嚼音 · 掏耳】)[YouTube][百合音声同好会][2024]](https://yuri.website/wp-content/uploads/thumb/2024/01/【魔法少女にあこがれて】【fill_w372_h231_g0_mark_ASMR】マジアベーゼにいたずらされて【耳ふー・咀嚼音・耳かき】-KADOKAWAanime-1.webp)
![[在线/首发/音声/熟肉][RJ307502]どうしていつもこうなるのっ!?(为什么总是会变成这样啊!)[百合音声同好会][2020]](https://yuri.website/wp-content/uploads/thumb/2022/09/fill_w372_h231_g0_mark_37NG6581JV1_7UQ9P.webp)
![[下载/首发/音声/熟肉][YouTube]不会死去的她与忧伤的雨天[百合音声同好会][2021]](https://yuri.website/wp-content/uploads/thumb/2022/08/fill_w372_h231_g0_mark_PMH8X4FYWW_IW2K8NM92.webp)
![[下载/首发/音声/熟肉][RJ246088]ランドリー(White Laundry Magnolia)[百合音声同好会][2019]](https://yuri.website/wp-content/uploads/thumb/2022/08/「ランドリー」イメージイラストfill_w372_h231_g0_mark_.webp)









2022.04.18更新脚本文件(把已整理本子同步更新了)。
此方法使用网站为nheitai
以https://nhentai.net/g/392051/为例
链接点进去页面如下:
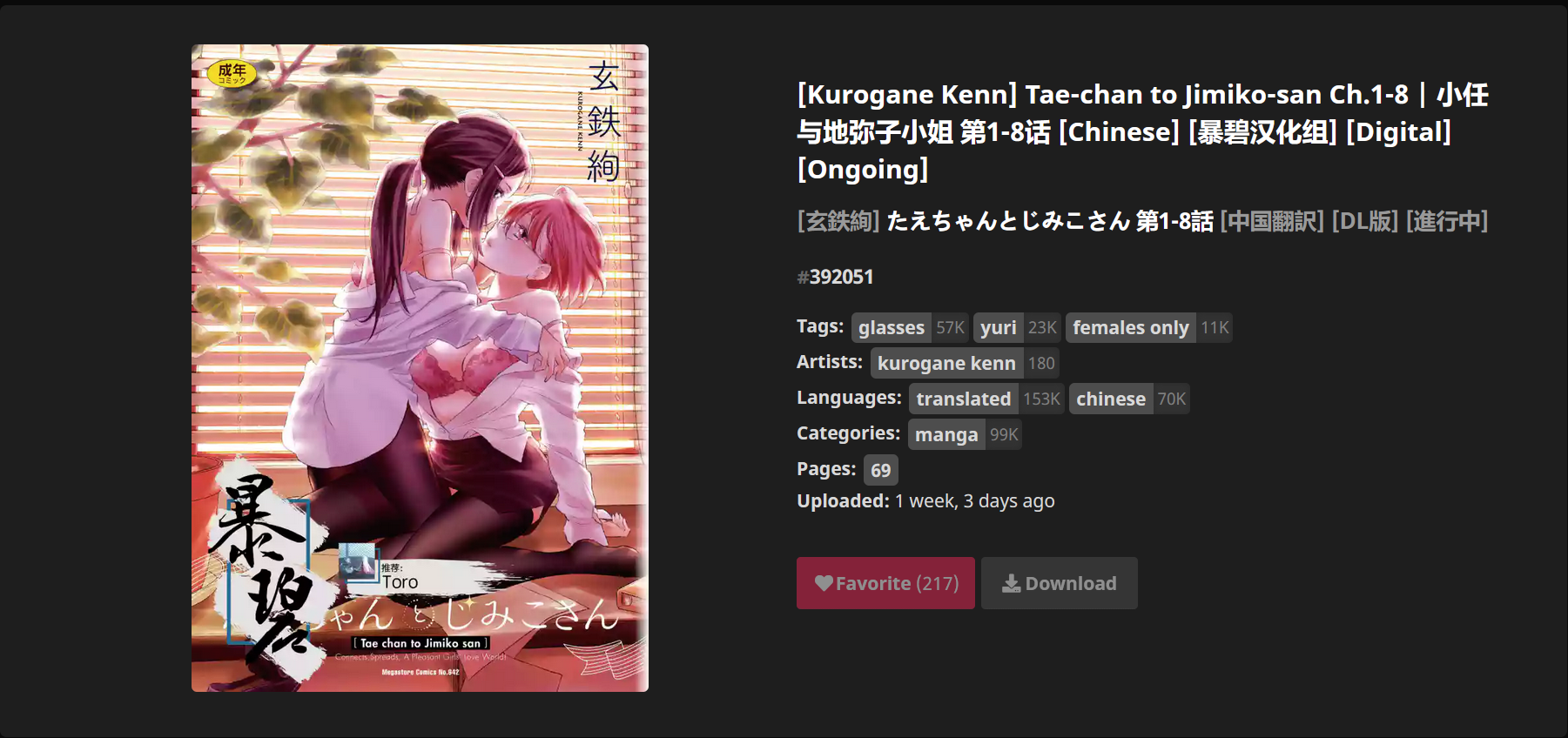
我们需要的信息是本子标题和页数,复制如下
[玄鉄絢] たえちゃんとじみこさん 第1-8話 [中国翻訳] [DL版] [進行中]
69
接下来往下翻网页点击图片进行阅读
对加载的图片选择‘复制图片链接’
手机端则是长按图片选择‘查看图片’,然后在上方网页框中复制链接
链接如下:https://i.nhentai.net/galleries/2142410/1.png
需要的信息为编号和图片格式,复制如下
注意:是链接里的编号而不是页面里#后的数组
2142410
.png
至此,我们已经集齐了所需的全部元素,整理如下
[玄鉄絢] たえちゃんとじみこさん 第1-8話 [中国翻訳] [DL版] [進行中]
69
2142410
.png
格式如下(全部都要用英文符号):
[“作者”,
[“本子标题”,页数,”/编号/”,”格式”],
[“本子标题”,页数,”/编号/”,”格式”],
……
“本子标题”,页数,”/编号/”,”格式”],]
以此本子为例则
[“[玄鉄絢] たえちゃんとじみこさん 第1-8話 [中国翻訳] [DL版] [進行中]”,69,” /2142410/“,”.png”],
之后使用文章附件里的脚本即可下载,脚本里有已整理过的本子信息。

唔,,网址打不开,挂了梯子也好像没用
我这里挂梯子就可以打开,之前是不需要梯子的,现在可能是被墙了。
大佬好强,我一直都是拿IA一本本扫来下的。。。
这好麻烦啊,。。。
感谢教授!
感觉有一点点麻烦,是不是可以做到,直接复制那个本子的url连接然后脚本自动爬取这些东西,自动下载。
刚发现nht上了五秒盾,不过可能可以用cloudscraper绕过。实在不行就用js了
感谢指导,终于会了
学到了,我去试试!感觉可以下一些
感谢大佬!之前一直都很苦恼来着,这下有解决方法了
有点难办啊,打不开,,